今回はデータサイエンスのエントリです。
自然言語処理を勉強し始めたんですが、これが中々奥が深く、ちょこちょことメモがわりに書くことにしました。自然言語処理というのはざっくり言えばテキストをあるルールで分類し、そこから何かしらのインサイトを得ようという試みです。今回はその中でも感情分析についての入門を書きます。以下では
・感情分析とは何か?
・感情分析をすることの難しさ
について書いていきます。
まず感情分析とは、テキストで表現された個別の感情を識別するプロセスです。これを分析することによって
・マーケティング
・広告
・レコメンデーションシステム
なんかに応用できるんですね。SNS等での感情がわかれば売上の向上や炎上回避にも繋がるということで結構企業でもやられているみたいです。
ところがどっこい、これが2つの理由で難しい。1つは「感情の分類ってなんぞや?」というものと、もう1つが「文章からどうやってやるの?」ということです。順に見ていきましょう。
そもそもの感情の分類ってなんぞ?という話です。これはもはや心理学の話なので、そこまで詳しく書けません笑笑。確かに言えることは
感情の統一的な分類はない
って事です。まぁ、学者での論争が絶えないんでしょう。ただ以前に紹介した性格6分類(外交性とか)にあるように、感情もある程度統一されつつある様です。参考文献によると大体主流なのが
・感情離散モデル
エクマンの6つの基本感情 (悲しみ、幸福、怒り、恐怖、嫌悪、驚き)など
・感情の次元モデル
プルチックの円状モデル
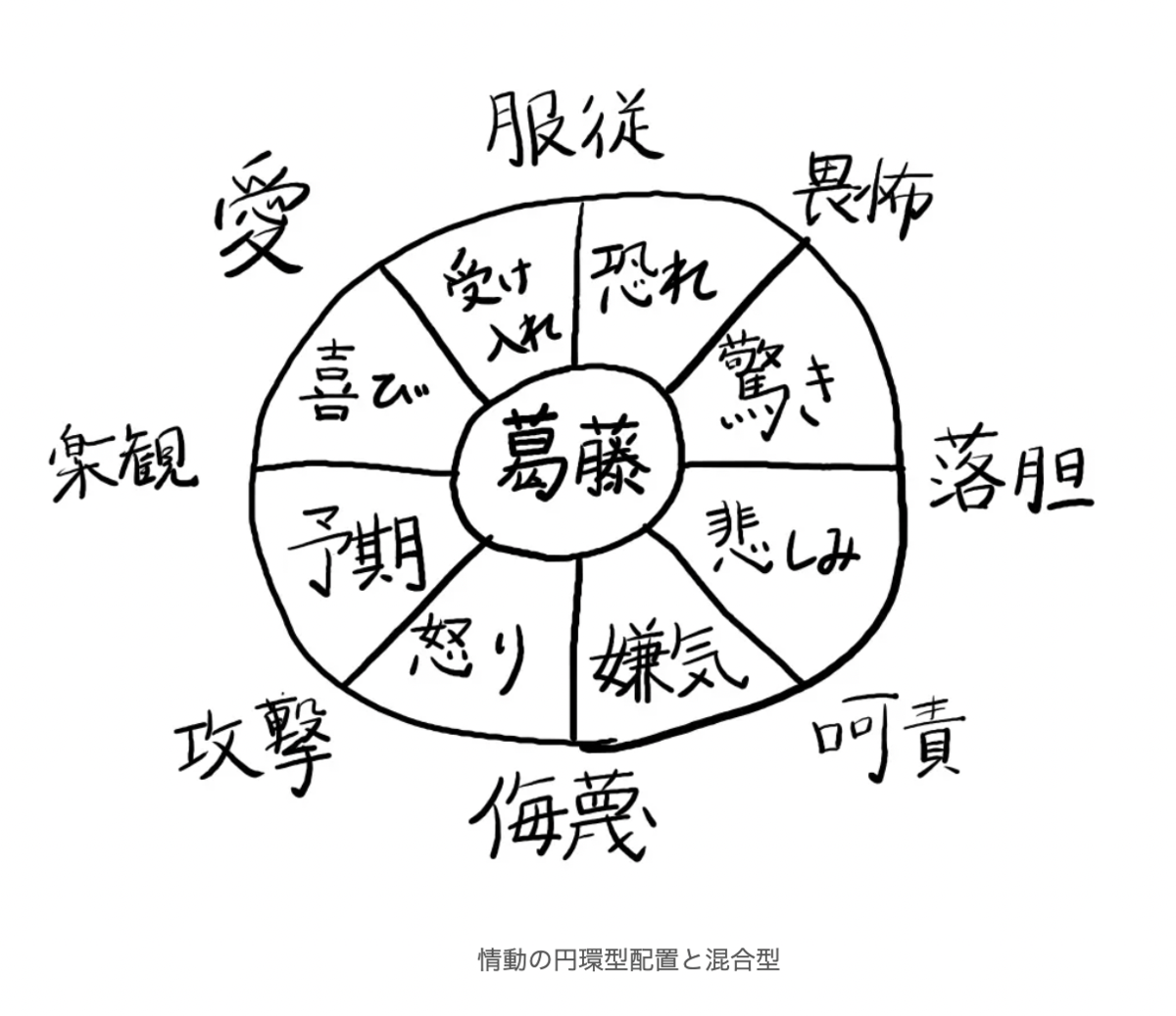
の2つです。後者には感情通しのつながりを読み取れるかと思います。
まず、感情検出は、機械学習と自然言語処理の複数の問題を組み合わせたマルチクラスの分類タスクです。
2 つ目は、感情言語の複雑な性質 (たとえば、感情の暗黙の表現、比喩など)、および人間の感情の複雑さに由来する、
テキストでの感情表現のとらえどころのない性質です。
2でどのように分類されているか
3でタスクの言語的な複雑さの背後にある理由
テキストから感情を読み取れるの?
という問題です。
実際に起こった顔を見れば大体の人は怒っていると判断しますが、これが文章だと間接的に感情を伝えている場合があるからです。
例えば、怒りに関して言えば
私は怒った
とあればこれは怒りと分類できますが、
私は冷静さを失いました
であれば、恐怖なの?とも解釈できます。こう言ったものをどう処理したりするのか?というところが自然言語の難しさです。次回はその辺のお話を書いていきます。